元字符
元字符是具有特殊意义的字符,其定义在正则表达式中并不是统一的。元字符在字符组外和字符组内意义不一样。
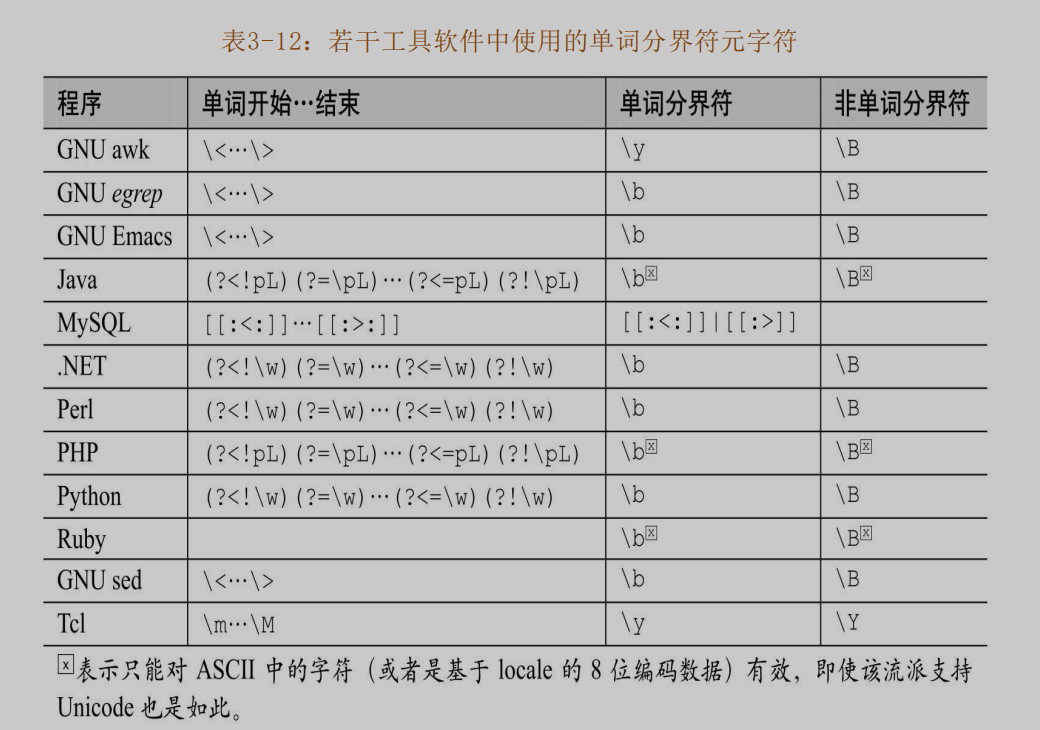
^: 脱字符,开头锚点$:美元符,结尾锚点[]: 字符组[^]:排除型字符组.:点号,单个任意字符(字符组外部)\<:单词起始位置(某些egrep可能不支持,perl使用\b)\>:单词结束位置(某些egrep可能不支持,perl使用\b)|: 或者,也叫多选分支(多选项),分隔两边表达式():限制竖线(多选项)范围;字符组成单元,受量词作用;反向引用捕获文本(?:):只分组不捕获,及得到的文本不会保存到变量中,不影响捕获计数
量词:
?:可选项,前元素出现0/1次+: 重复出现,前元素>=1*:重复出现,前元素>=0
区间量词:
{}:自定义重现次数符号 o{n,m} 前一个字母o,至少连续出现n次,最多连续出现m次 ≥n ≤m o{n} 前一个字母o,连续出现n次 ==n o{n,} 前一个字母o,至少连续出现n次 ≥n o{,m} 前一个字母o,最多连续出现m次 ≤m
\1,\2:反向引用 (匹配第一组、第二组括号内字表达式匹配的文本)
\: 转义符
-:字符组内:普通符号([之后,[^之后)、表示范围
.*:一组任何字符(某些工具中,不包括换行符)
| 符号 | 含义 |
|---|---|
| 制表符 | |
| 换行符 | |
| 回车符 | |
| 任何空白字符(whitespace character):空格符、制表符、进纸符、回车符 | |
| 除 | |
| 即[a-zA-Z0-9] 可使用 +来匹配一个单词 | |
除,也就是[^a-zA-Z0-9] |
|
| [0-9],即数字 | |
除,即[^0-9] |
Tips
一个字符组,即使是排除型字符组,也需要一个字符
字符组只能匹配一个字符,多选项匹配任意长度文本
锚点可以分为两大类:简单锚点(^、$、…)和复杂锚点(例如顺序环视和逆序环视)。
egrep的正则使用:
egrep '^(from|subject):' file
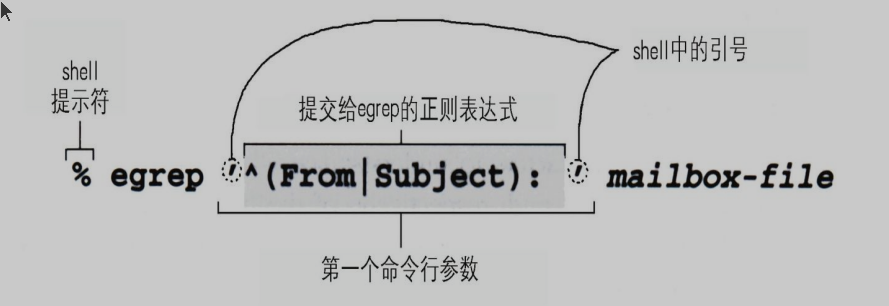
(first|lst)=(fir|l)st^a|b|c:.与^(a|b|c):.不一样,括号的作用就是分组\<cat\>:单词分界符(不是所有egrep都支持),匹配cat,单词版本的^和$

反向引用
匹配与表达式先前部分匹配的同样的文本。
([a-z])([0-9]) \1\2:\1代表[a-z]匹配的内容,\2代表[0-9]匹配的内容
匹配the the:
\<the the\>\<(A-Za-z+) +\1\>比第一种找到的范围更大
1 | $price=~s/(\.\d\d[1-9]?)\d*/$1/ |
环视(断言)
选择一个位置:顺序环视,即从左到右,匹配字符,最后回到原点即左边,肯定则有该匹配字符,否定则没有;逆序环视,即从右往左,匹配字符,最后回到原点即右边,肯定则有该匹配字符,否定则没有;所以找到字符在右的,使用顺序环视,找的字符在左的,使用逆序环视。

正向先行断言:正向顺序环视 负向先行断言:否定顺序环视 正向后行断言:肯定逆序环视 负向后行断言:否定逆序环视
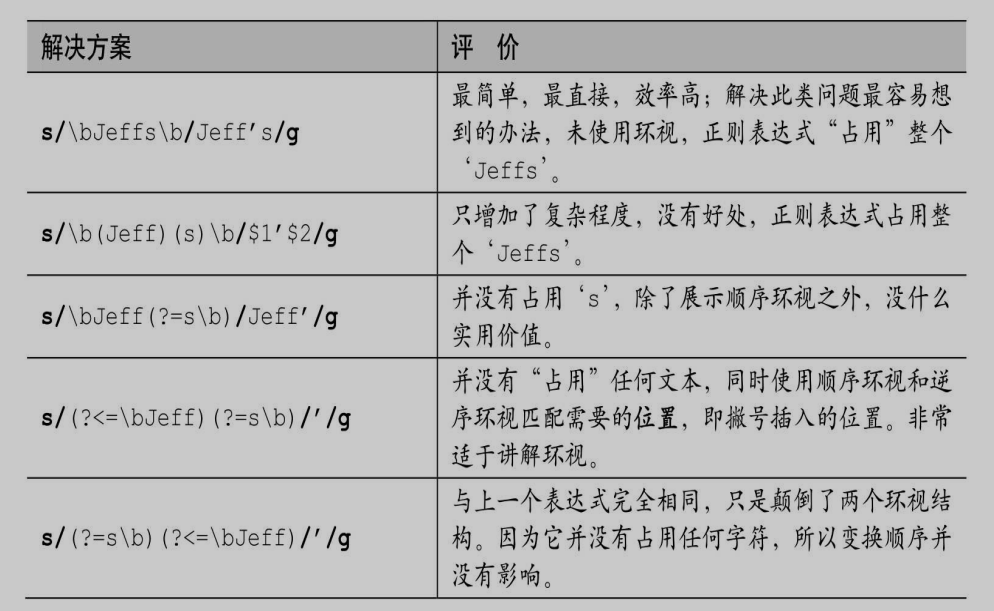
(?=jeffrey)jeff=jeff(?=rey):都能精确匹配第一行,第二行不会匹配
jeff:两行都能匹配到
1 | jeffrey |
其他
程序设计语言有 3 种处理正则表达式的方式:集成式 (integrated)、程序式(procedural)和面向对象式(object oriented)。在第一种方式中,正则表达式是直接内建在语言之中的,Perl就是如此。Python采用的是面向对象式的办法。Awk 使用的是集成式处理方法。
1 | import re |
宽松排列和注释模式 :此模式会忽略字符组外部的所有空白字符。字符组内部的空白字符仍然有效(java.util.regex是例外),#符号和换行符之间的内容视为注释。
点号通配模式(dot-match-all match mode,也叫“单行模式”):通常,点号是不能匹配换行符的。对现代编程语言来说,点号能够匹配换行符的模式和不能匹配的模式同样有用。这两种模式哪个更方便,取决于具体的情况。许多程序提供了两种方法供正则表达式选择。
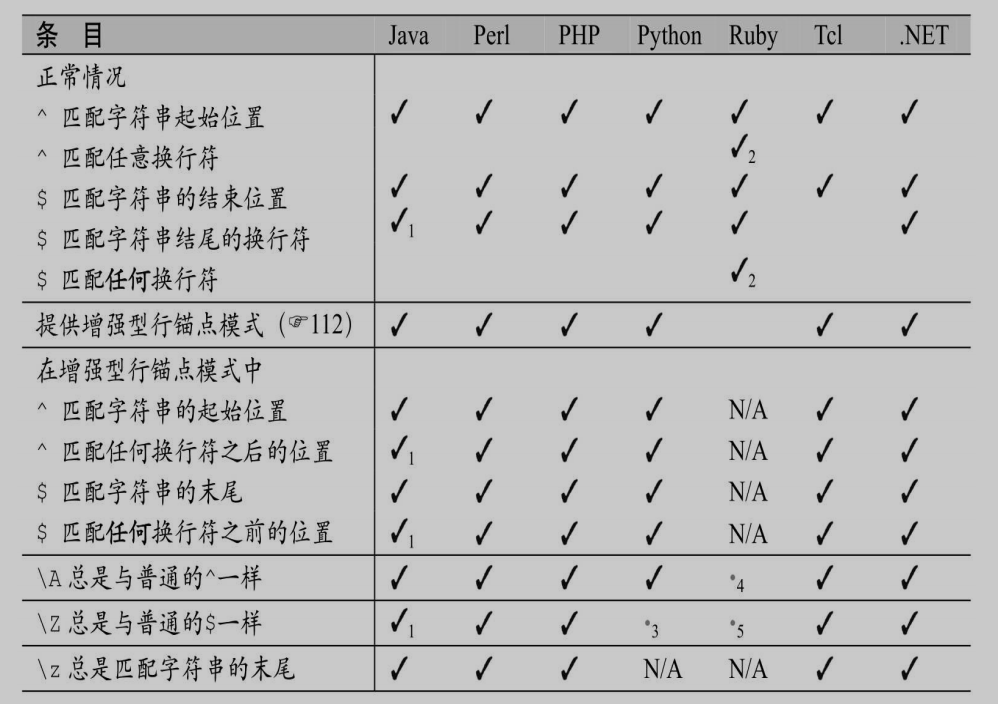
增强的行锚点模式(Enhanced line-anchor match mode,也叫 “多行文本模式”):增强的行锚点模式会影响到行锚点「^」和「$」的匹配。通常情况 下,锚点「^」不能匹配字符串内部的换行符,而只能匹配目标字符串 的起始位置。但是在此增强模式下,它能够匹配字符串中内嵌的文本行的开头位置。
文字文本模式:“文字文本(literal text)”模式几乎不能识别任何正则表达 式元字符。
字符组通常表示肯定断言(positive assertion)。也就是说, 它们必须匹配一个字符。排除型字符组仍然需要匹配一个字符,只是 它没有在字符组中列出而已。
在某些工具软件中,点号用来缩略表示可以匹配任何字符的字符 组,而在其他工具中,点号能匹配除了换行符之外的任何字符。
简单的字符组减法:[[a-z]-[aeiou]]
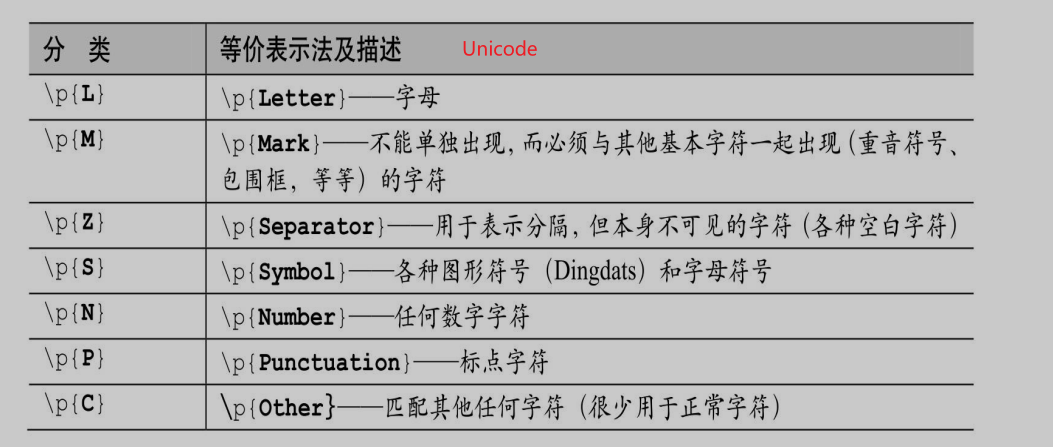
完整的字符组集合运算:[[a-z]&&[^aeiou]]
推荐阅读
- Regex Learn - 逐步从零基础到高阶。
- Road 2 Coding (r2coding.com)
- 正则表达式30分钟入门教程 (deerchao.cn)
- 精通正则表达式(effrey E. F. Friedl):本文的绝大多数内容来源