森林图是以统计指标和统计分析方法为基础,用数值运算结果绘制出的图型。用以综合展示每个被纳入研究的效应量以及汇总的合并效应量[1]。
连续变量
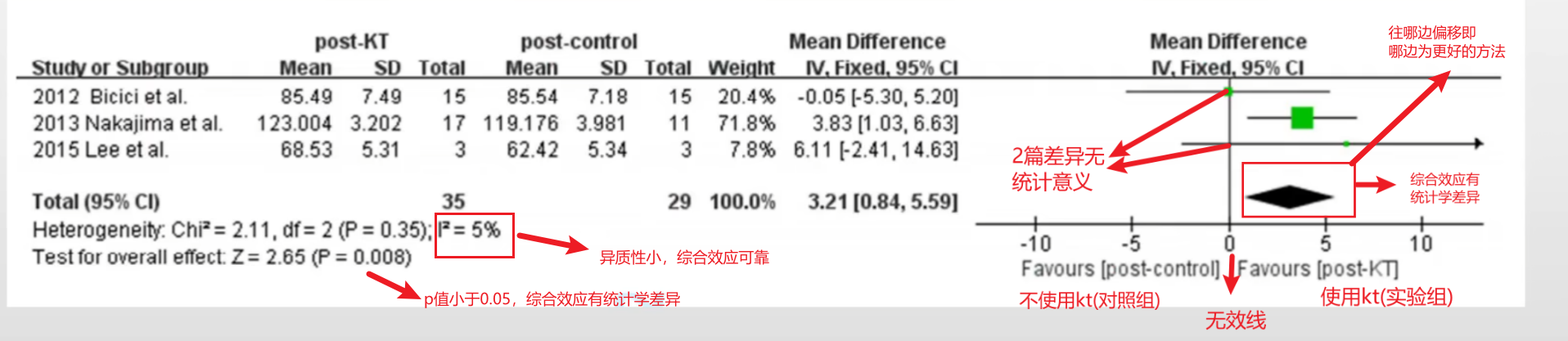
异质性\(I^2\),它的数值代表这三篇RCT有没有明显差异,差异越小说明得出综合效应的结果越可靠,小于20%说明异质性小,大于50%说明异质性较大。
favours代表菱形框往哪边偏倚支持那边就是更好的方法。
综合效应如果贴到无效线,则无显著差异:
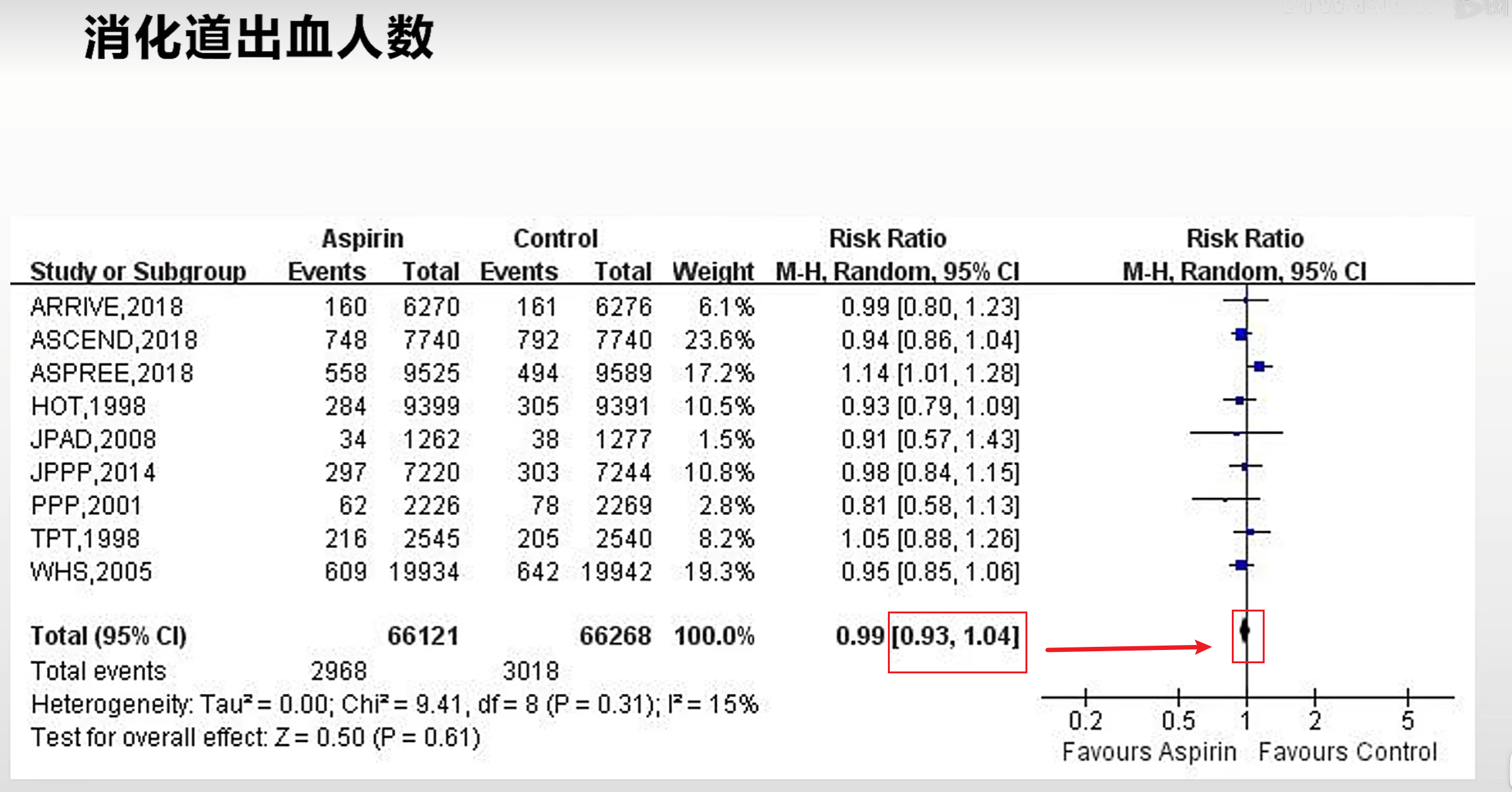
森林图:
- 随机效应模型(Random):随机效应模型是把每一篇RCT的影响力对等,不按它的样本量,把每一篇RCT平均影响综合效应表示出来。
- 固定效应模型(Fixed):固定效应模型是按它的样本量将样本量大的RCT影响权重加大,纳入人群更多的RCT的结果将更影响综合效应。
一般我们推荐用随机效应模型,因为每一篇RCT都是独立个体,都应均等地影响综合效应,但是一种情况除外那就是其中一个RCT样本量非常大,而其他RCT样本量寥寥无几,那么显然这个样本量大的RCT结果更可靠,更应该权重放大,这就选择固定效应模型。其实不管选择什么模型,做好必要解释就行。
二分类变量
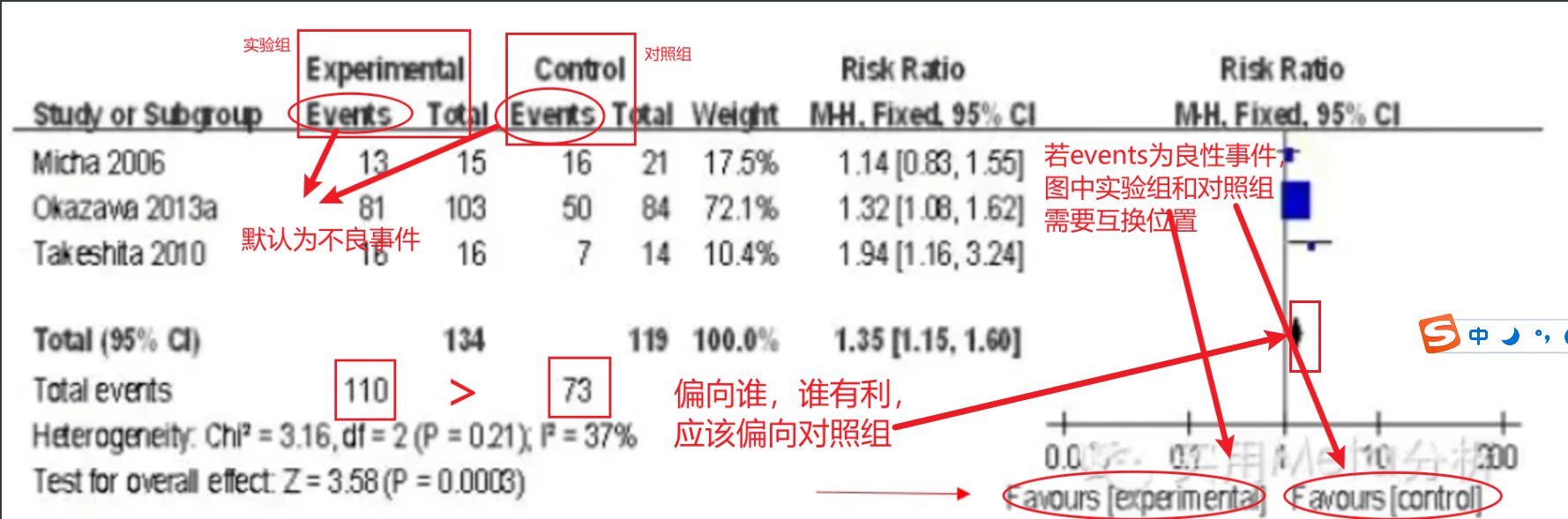
刚刚的图是连续变量,就是用平均值和标准差做比较。而有些结果是通过二分类变量展示的,比如说治愈率,就是总的人数(Tota)和治愈的人数(Events)。软件会自动将Events.定义为不良事件,所以事件发生次数越少,越偏向有利。但是像治愈这种良性事件,我们就需要把下边这个标记换个顺序即可。